Learning Agentic AI the Hard Way: Building a Trading Bot That Refuses to Guess
TradeX is my test bed for agentic AI: a trading research system that has to investigate, challenge, backtest, and prove ideas before it is allowed to act.
On this page
- The first version was too confident
- The orchestrator is not there to be clever
- The research desk
- Structured outputs beat impressive paragraphs
- Synthesis is where duplicate evidence gets punished
- Code is not progress if the idea is weak
- The risk gate is intentionally boring
- Paper trading is another research input
- The architecture is simple on paper
- Memory has to be selective
- The system is built around distrust
- What TradeX is really testing
I did not start TradeX because I wanted another trading bot that throws indicators at a chart and calls it intelligence.
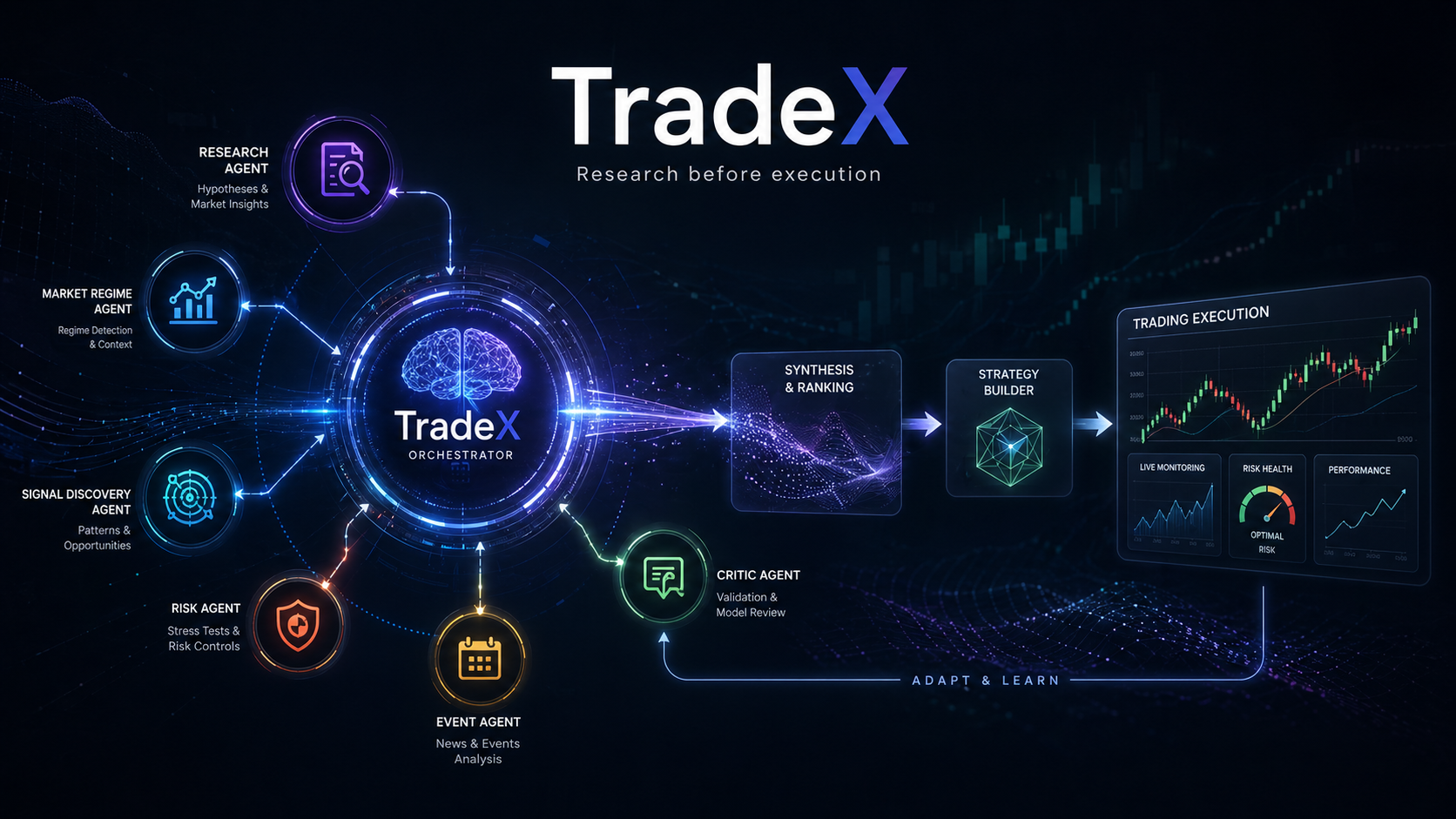
TradeX multi-agent research loop architectureClick to inspect full size
There are enough of those already.
Most trading bots I studied had the same weakness: they behaved as if the market was a clean engineering problem. Feed in price data. Add indicators. Backtest. Optimize. Deploy. Watch the thing slowly become confused when reality changes.
That is not how markets behave.
A strategy that works during a quiet, low-volatility period can break when inflation data comes out. A signal that looks strong in a backtest can become useless when liquidity dries up. A model can be technically correct and still lose money because it ignored context. The market is not just a time series. It is a moving system of participants, incentives, constraints, news, positioning, liquidity, and regime shifts.
So I wanted to test a different idea.
What if the bot does not start by trading?
What if it starts by researching?
TradeX became my test project for that question.
Not a toy chatbot sitting next to a trading screen. Not a single model asked to "find a good strategy." I wanted a system that behaves more like a small research desk: one part looks at market structure, another studies signals, another checks risk, another challenges the assumptions, and one central orchestrator keeps the work moving.
That sounds clean when written in one sentence.
In practice, it gets messy fast.
The first version was too confident
The first version was almost embarrassingly linear. I gave the model a task like this:
Find a trading strategy for current market conditions.It would return something that looked reasonable. Maybe a momentum strategy. Maybe mean reversion. Maybe a regime-based approach. The answer was structured, confident, and mostly useless.
The problem was not that the model was stupid. The problem was the workflow.
A single agent tries to compress too much into one context. It researches, decides, critiques itself, and builds the final answer. That is convenient, but it creates a dangerous pattern: the same reasoning that created the idea is also responsible for judging whether the idea is weak.
That is how bad assumptions survive.
In a normal engineering task, this is already risky. In trading, it is worse, because a plausible explanation can hide a broken edge for a long time. "Momentum is strong" sounds useful until you ask whether the signal survives spread, slippage, volatility expansion, and the exact period you accidentally optimized against.
So I changed the shape of the system.
The orchestrator is not there to be clever
TradeX now starts with an orchestrator. Its job is not to invent trades. Its job is to divide the work, enforce boundaries, and decide how much effort the question deserves.
When a market question enters the system, the orchestrator does not immediately ask for a strategy. It first asks what kind of problem it is dealing with:
question_type: strategy_research
market_context: incomplete
required_tracks:
- hypothesis_generation
- market_regime
- signal_discovery
- risk_research
- event_interpretation
- strategy_criticism
stop_condition: enough_evidence_to_test_or_rejectThat small routing step matters. A narrow question does not need a swarm. A broad question does. If the market context is unclear, the system explores wider before it narrows. If the strategy is already defined, the system should stop researching and start testing.
The orchestrator has to control effort.
That might be the most underrated part of the design. A bad orchestrator turns an agent system into noise. A good orchestrator gives every agent a clear job, a boundary, an output format, and a reason to exist.
The research desk
Once the orchestrator has scoped the request, it assigns research tracks.
The hypothesis agent looks for possible edges. It might suggest a breakout setup, a mean-reversion idea, a volatility filter, or a regime-specific allocation rule.
The market regime agent asks what kind of environment the strategy would be entering. Low volatility and tight spreads are not the same world as macro-event volatility and thin liquidity.
The signal discovery agent studies whether the signal is actually distinct. A lot of indicators are just momentum wearing a different shirt.
The risk agent ignores the exciting part and looks for ways the trade can hurt. Drawdown concentration, tail exposure, correlation, liquidity mismatch, and position sizing all matter more than a pretty entry rule.
The event agent watches the outside world. Earnings, inflation prints, central bank decisions, geopolitical shocks, exchange outages, and sector rotations can all change whether a signal is meaningful.
Then there is the critic.
That last agent matters.
A trading system that only searches for reasons to enter a trade is not a trading system. It is a confirmation machine.
The critic agent asks the questions that make the rest of the system uncomfortable:
- Why would this edge still exist?
- Is the backtest benefiting from one specific period?
- What happens if volatility doubles?
- Is the signal just another way of measuring momentum?
- Does the strategy survive transaction costs?
- Is the model adapting, or just overfitting with nicer words?
- What evidence would force us to reject this idea?
This is where TradeX started to feel different.
The system was no longer trying to produce one clever answer. It was creating tension between agents. The hypothesis agent might suggest a breakout setup. The market regime agent might say the current environment is too choppy. The risk agent might flag drawdown concentration. The critic might reject the whole thing because the idea only works when tested on a narrow slice of history.
That conflict is useful.
It slows the system down in the right place.
Structured outputs beat impressive paragraphs
The research agents do not just return "interesting findings." That is too vague to automate. TradeX needs outputs that can be compared, ranked, tested, and challenged.
So each research agent returns a compact structure:
{
"hypothesis": "Breakout continuation after volatility compression",
"evidence": [
"Range compression over the last 20 sessions",
"Volume expansion on upward breaks",
"Sector relative strength improving"
],
"market_condition": "Low realized volatility with rising event risk",
"assumptions": [
"Liquidity remains stable",
"Breakouts are not immediately faded",
"Transaction costs stay within tested range"
],
"invalidation_criteria": [
"False breakout rate rises above threshold",
"Average slippage exceeds modeled cost",
"Signal only works in one historical window"
],
"risk_notes": [
"Potential crowding in momentum names",
"Drawdown may cluster during macro releases"
],
"suggested_test": "Walk-forward backtest with volatility regime labels",
"confidence": 0.62
}This makes the next step possible. The synthesis engine can compare ideas instead of reading essays. The backtesting engine can convert hypotheses into experiments. The critic can attack assumptions directly.
That is where TradeX starts to look less like a chatbot and more like a research machine.
Synthesis is where duplicate evidence gets punished
After the research agents finish, the synthesis layer takes over. It does not treat every finding equally.
This is important because agent systems can accidentally create fake consensus. If three agents say the same thing in different words, that is not three pieces of evidence. It is one idea repeated three times.
The synthesis engine has to merge overlap, remove weak candidates, and separate independent evidence from repeated reasoning. It ranks ideas by evidence quality, testability, risk, and disagreement.
A useful candidate is not the one that sounds best. It is the one that can be tested cleanly.
The synthesis layer is looking for outputs like this:
{
"candidate": "Volatility-filtered breakout strategy",
"rank": 2,
"why_it_survived": [
"Distinct hypothesis",
"Clear invalidation criteria",
"Testable against multiple volatility regimes"
],
"main_objection": "May be a disguised momentum strategy",
"next_action": "Build minimal backtest with cost and slippage model"
}That main_objection field is not decoration. It travels with the strategy into testing. If the backtest ignores the objection, the test is incomplete.
Code is not progress if the idea is weak
The strategy builder only enters after synthesis.
This was an important design decision. I did not want TradeX to generate code too early. Code gives a weak idea a false sense of progress. Once something turns into a backtest, it starts feeling real. Charts appear. Metrics appear. Sharpe ratio appears. Suddenly the idea looks more serious than it deserves.
So TradeX has to earn the right to build.
Only after the research layer produces a candidate does the system move into construction:
- strategy definition
- backtesting
- robustness checks
- stress testing
- risk gate
The strategy definition has to be boring and explicit. Entry condition. Exit condition. Universe. Timeframe. Position sizing. Data sources. Fees. Slippage. Rebalance rules. Invalidation criteria. If those are not written down, the system is still guessing.
The backtest is not allowed to be the whole argument. It is only one experiment.
The risk gate is intentionally boring
The risk gate is not there to be creative. It blocks strategies that fail basic sanity checks.
Too much drawdown. Blocked.
Too few trades. Blocked.
Performance concentrated in one short period. Blocked.
Good return but terrible risk-adjusted behavior. Blocked.
Strong backtest but weak logic. Blocked.
In simplified form, the gate looks like this:
def risk_gate(result):
if result.max_drawdown > 0.18:
return "blocked: drawdown too high"
if result.trade_count < 100:
return "blocked: sample size too small"
if result.profit_concentration > 0.45:
return "blocked: returns too concentrated"
if result.cost_adjusted_sharpe < 1.0:
return "blocked: weak risk-adjusted performance"
if not result.logic_matches_research_claim:
return "blocked: backtest does not prove the hypothesis"
return "approved_for_paper_trading"The numbers are not universal. They depend on the market, timeframe, asset class, and strategy type. The point is the shape of the gate: the system should not promote a strategy just because it found a nice chart.
The risk gate also protects against a common AI failure mode: fluent rationalization. A model can explain a bad result in a way that sounds reasonable. The gate does not care. It checks the rule.
Paper trading is another research input
If a strategy survives, it does not go directly to live trading. It goes to paper trading first.
The live monitor watches for drift, anomaly, execution quality, and behavior changes. If the strategy starts acting differently from the tested version, the system feeds that information back into the research layer.
That feedback loop is the real product.
Most bots treat deployment as the end. TradeX treats deployment as another research input.
The market changes. The strategy changes. The evidence changes. The system should know when yesterday's answer is no longer good enough.
The live monitor is not only asking, "Is this profitable?" It is asking:
- Are fills worse than expected?
- Is slippage drifting?
- Is the signal firing too often?
- Is the strategy entering different regimes than the backtest covered?
- Are losses clustered around specific events?
- Has the correlation profile changed?
Those observations become new evidence. New evidence can reopen the research loop.
That is the part I care about most.
The architecture is simple on paper
The architecture is not complicated when reduced to boxes:
Data inputs
-> Orchestrator
-> Parallel research agents
-> Synthesis and ranking
-> Strategy construction
-> Risk gate
-> Paper trading
-> Live monitoring
-> Memory and feedbackThe hard part is not drawing the boxes.
The hard part is making the boxes behave.
Agents can duplicate work. They can over-research simple questions. They can miss obvious context. They can produce strategies that sound smart but collapse under transaction costs. They can also become too cautious and reject everything.
That is where the engineering starts.
TradeX needs memory, but not unlimited memory. It needs agents, but not a swarm for every tiny task. It needs autonomy, but also hard gates. It needs creativity during research and strictness during validation.
I learned quickly that more agents is not automatically better.
If the task is narrow, one agent is enough. If the task is broad, parallel research helps. If the market context is unclear, the system needs wider exploration before it narrows. If the strategy is already defined, the system should stop researching and start testing.
The orchestrator has to make that call.
Memory has to be selective
TradeX needs memory because markets have history. It needs to remember tested strategies, rejected hypotheses, event context, parameter choices, failure cases, and live observations.
But unlimited memory is not intelligence. It is just a larger pile of things to be wrong about.
The memory layer has separate responsibilities:
- research memory stores hypotheses and intermediate findings
- strategy archive stores tested strategies, parameters, configurations, and results
- experiment log stores test runs, metrics, and outcomes
- market context history stores regimes, macro context, events, and correlations
The orchestrator should retrieve memory only when it is relevant to the current task. A failed crypto momentum strategy from a high-volatility regime should not automatically pollute research for a low-volatility equity mean-reversion question.
Memory needs scope.
Without scope, an agent system starts confusing "I have seen something like this before" with "this evidence applies now."
The system is built around distrust
I still do not trust TradeX blindly.
That is the whole point.
The system is designed around distrust. Every idea has to pass through friction. Every agent output can be challenged. Every strategy has to be tested. Every live result can reopen the research loop.
For me, that is the interesting direction for AI systems.
Not models that answer faster.
Systems that know when an answer is not enough.
TradeX is still a test project. It is not a promise of easy money, and it is definitely not a magic machine that prints trades. I am building it because trading exposes the weaknesses of agent systems very quickly. If the research is shallow, it shows. If the validation is weak, it shows. If the model is guessing, the numbers eventually expose it.
That makes it a useful place to learn.
What TradeX is really testing
The end goal is not just to build a bot that can trade.
The goal is to understand whether AI can run a full research-to-execution loop with enough discipline to be useful in the real world.
Trading is a good test environment because vague answers fail quickly. A confident paragraph is not enough. A beautiful explanation is not enough. A strategy either survives contact with data, cost, volatility, regime shifts, and risk limits, or it does not.
That makes TradeX useful as a model capability test. It forces the agent system to deal with open-ended research, incomplete information, changing conditions, noisy signals, and decisions that must be tested rather than believed.
TradeX starts with a simple belief:
Before an AI system is allowed to act, it should prove that it has done the work.
And in trading, proof does not come from a confident paragraph.
It comes from research, tests, failure cases, and the ability to change its mind when the market proves it wrong.
Hussam Ahmed
Building large-scale systems by day, exploring the universe by night.
Keep reading
Using LangGraph and LangChain to Orchestrate Codex and Claude Code in a Multi-Agent Engineering Workflow
How I used LangGraph and LangChain to coordinate Codex and Claude Code as separate planning, implementation, review, risk, and evidence agents inside the TradeX engineering workflow.
Read articleClaude Code Dynamic Workflows: A Practical Guide to the New Orchestration Feature
A practical guide to Claude Code dynamic workflows: what the new feature does, when to use it, how to trigger it, and how to design workflows that split, verify, loop, and synthesize real engineering work.
Read articleFeatured project
See the Map Knowledge Graph reason about a live driving scene.
An interactive simulator with scenario switching, graph traversal, and step-by-step decision playback.
Follow new posts
I share build logs on AI systems, execution, and astrophotography as they ship — no schedule, only substance.